景观意象是旅游意象的重要组成部分,指的是游客主体和景观客体之间的映射,即主体对客体的想象与感知[1]。强烈的景观意象对游客的吸引力更强,是景观建设的基础与理论依据,也是提高旅游竞争力的重要途径。湖泊公园作为城市典型的蓝绿空间,提供着重要的生态调节服务与景观游憩服务,具有多种环境及社会效益[2],对于提高人类福祉和公共健康大有裨益,已经成为公众休闲放松、活动娱乐的重要城市开放空间。因此研究湖泊公园的景观意象有助于从公众角度完善湖泊公园的景观建设,但目前缺乏对景观意象的理论研究与系统化的感知挖掘分析。
随着互联网与人工智能的革新发展,使用社交媒体的人数以及来自大众网络公开数据的类型和数量呈指数级增长[3],网络平台端口的打通也为获取公开数据提供了支持[4]。基于大众网络媒介的数据源样本量大、公众参与程度高,能够更全面多维度地表达公众的感知偏好。目前来自Flicker、Panoramio、Twitter、微博、豆瓣等社交平台以及大众点评、携程等旅游网站的多源数据已被广泛应用于景观研究[5-8],在线旅游网站逐渐成为游客表达景区感知偏好和情感评价的重要途径[9]。
人们在各类网络平台分享的评论与照片,为相关研究贡献了海量的样本数据,目前基于网络文本的内容分析已经可以通过自然语言处理等方法实现自动化处理,然而基于照片数据的研究仍多依赖于手动编码和定性分析[10],这不仅使得分析结果易受到研究人员个体偏见和主观性的影响,还难以将其扩展到大型数据集和大尺度研究领域[11-13];而利用包含深度学习标签的大型图片数据集的研究则存在数据难以进行再处理,研究内容受限的问题[14]。
因此,通过计算机视觉算法处理大量图片数据来弥补手动编码的缺陷,目前已成为景观视觉和景观偏好研究的重要手段。在图像大数据集和云计算的推动下,计算机视觉应用程序的能力也迅速提升[15],目前可通过在线机器学习算法实现图像识别的平台包括Google Cloud Vision①、Microsoft Azure、Clarifai及百度智能云,其中Google Cloud Vision提供的图像识别API可以通过预训练的机器学习算法识别图像中的特定对象,包括人、动物、物体、标志等,提取图片颜色以及识别文本;除此之外,还提供了基于研究人员分类标签的自定义模型程序,为实现特定研究提供了条件。
目前Google Cloud Vision在国外已被应用于国家、城市、自然保护区、国家公园等对象的生态系统文化服务、景观美学等研究[16-19],已成为实现大规模图像内容分析的前言技术方法。
鉴于此,本研究开发了一个新框架来综合分析大规模图像数据,通过Google Cloud Vision提供的在线机器学习算法,自定义景观标签,构建AutoML模型对武汉市7个湖泊公园的16883张网络景观照片进行图像挖掘与内容识别,归纳景观意象的具体维度,分析研究地的景观意象特征及感知偏好,为提升研究地的景观吸引力提供建议。
1研究设计
1.1研究区域概况
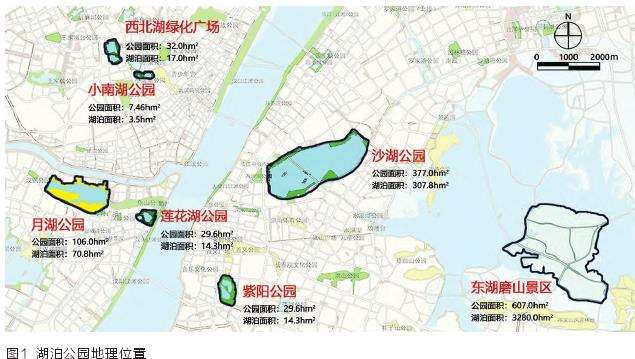
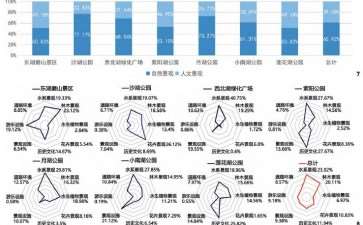
武汉位于中国中部地区,是湖北省省会,地处古云梦泽地带,市内湖泊众多,素有“百湖之市”之称,现有大小湖泊166个。湖泊不仅是武汉市重要的生态系统,也是城市历史文化的源流,是城市形象的重要标志。本研究以武汉市为例,根据公园面积、公园类型、地理位置等公园属性选取了7个具有代表性的湖泊公园作为研究对象 (图1,表1)。
1.2数据收集与预处理
本研究的照片数据来源于在线旅游网站上游客的评论图片,考虑到社交媒体平台 (微博、小红书等) 用户数据的私密性以及平台本身的隐私政策,在此不予考虑。本研究选取大众点评网、携程网、马蜂窝旅游网3个受众性高、评价数据量大的国内主流旅游网站,通过网络爬虫进行照片检索与爬取,时间跨度为2018年4月26日 \sim 2021年4月26日,爬取7个公园所有的游客评论图片,共21674张。随后对照片数据进行预处理,剔除模糊照片、同一评论者上传的相同照片以及以人像、食物、地图、门票、广告等为主的非景观照片,最后保留16883张景观照片 (表1)。
1.3研究方法
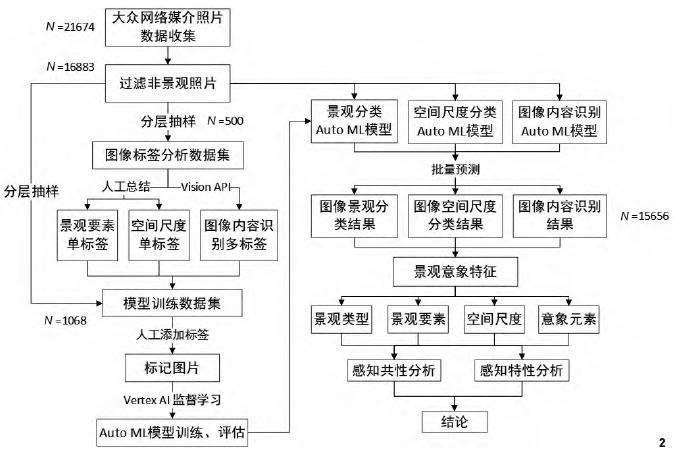
本研究应用Google Cloud Vision提供的在线机器学习算法分析网络照片,运用图像识别应用程序编程接口 (Vision API) 和 VertexAI平台来识别图像内容、自定义景观标签以及创建、训练、评估AutoML (Automated Machine Learning,自动机器学习) 模型,最后利用AutoML模型批量预测景观照片得到图像识别结果,通过统计分析、分类总结等方法探讨研究地景观意象的特征及公众偏好,分析其感知共性与特性。具体研究思路如图2所示。
2研究分析
2.1图像标签分析
将景观照片数据集按不同公园分为7层,在各层中通过分层定比,即按2.96\%的样本比例,在各层中进行简单随机抽样,共抽样出500张照片,用于图像标签分析。根据景观特征和相关研究,通过人工识别对500张样本照片进行景观分类和空间尺度分类,通过Vision API对样本照片进行图像内容识别。
1)单标签-景观要素:景观要素可归纳总结为两大类型、8项要素。其中自然景观包括水体景观、林木景观、花卉景观、水生植物景观;人文景观包括历史文化 (以传统的亭台楼阁、历史雕像等为主的文史景观)、景观设施 (以广场、景观小品等为主的硬质景观)、游乐设施、道路环境。
2)单标签-空间尺度:空间尺度可分为宏观、中观、微观和微距4类,宏观指110m见方以上的空间,中观指25 \sim 110m见方的空间,微观指25m见方以下的空间[20],微距在此指的是特写照片。
3)多标签-图像内容:Vision API基于预训练的机器学习模型,为每张照片返回带有置信度得分 (0 \sim 1) 的关键词标签[12]。通过设定为每张照片添加最多10个关键词标签,得到初始多标签数据库。提取所有置信度>0.5分的标签,并对标签数据进行检查,删除极低频率出现的标签 (flowerpot,coquelicot等) 和与研究需求无关的标签 (botany,symmetry等),归并相似意义的标签 (grass和meadow,building和architecture等),整合具有相同属性的标签 (monument,arts等),最后整理得到38个图像内容识别多标签 (表2)。考虑景观意象的复杂性和多元性,部分标签之间存在一定的交叉关系。
2.2模型训练
在景观照片数据集中按6.33\%的样本比例,在各层中进行简单随机抽样,共抽样出1068张照片,用于AutoML模型的训练与评估。首先人工为每张照片添加单标签与多标签,并保证每项标签至少有50张以上照片。其次将标记后的数据集按照80\%、10\%和10\%的比率拆分为训练集、验证集和测试集。最后VertexAI通过监督学习,训练AutoML模型。
2.3AutoML模型评估
2.3.1景观分类模型评估
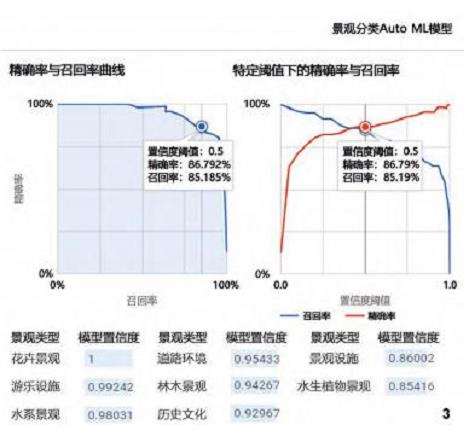
武汉景观分类模型的平均精确率为0.946,在置信度阈值为0.5时,精确率为86.8\%,召回率为85.2\% (图3),总体来看模型精度较高,各项指标均大于0.85。评估结果表明模型可以较好地分类所有景观类型,其中对游乐设施、水体景观、花卉景观的识别能力最好 (置信度>0.95,正确预测比率>85\%);但对景观设施和历史文化以及水生植物景观和林木景观之间存在一定程度的混淆,混淆比率分别为27\%和25\%,原因可能在于2组景观要素的部分样本包含了重叠或相似的景观内容,考虑到景观的复杂性和人工识别误差,该部分误差可认为是正常结果。
2.3.2空间尺度分类模型评估
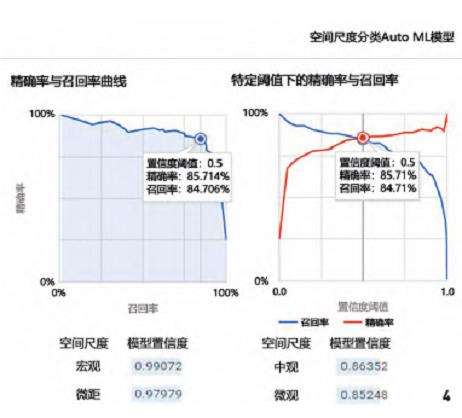
空间尺度分类模型的平均精确率为0.887,在置信度阈值为0.5时,精确率为85.7\%,召回率为84.7\%,且各项标签的模型置信度得分均大于0.85 (图4)。评估结果表明模型可以较好地分类所有空间尺度,其中对微距尺度景观的识别能力最好 (置信度得分>0.95,正确预测比率>85\%)。
2.3.3图像内容识别模型评估
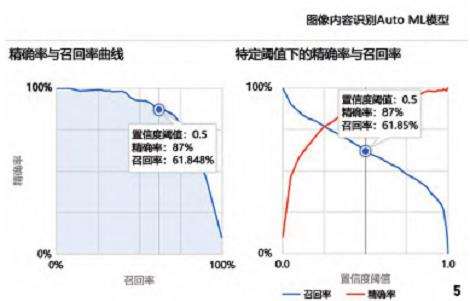
图像内容识别模型的平均精确率为0.834,在置信度阈值为0.5时,精确率为87\%,召回率为61.8\% (图5)。由模型置信度得分 (图6) 可知所有标签中置信度>0.5的有35项 (占92.1\%),即绝大多数标签满足模型用于内容识别的要求;置信度>0.8的标签过半,大于0.95的标签超过1/4,即模型在精确识别部分标签方面表现良好。其中模型对花瓣、主题雕塑、摩天轮、台阶、缆车、夜景6项标签的识别能力最好 (置信度=1),对水上栈道、拱桥和落叶树几项标签的识别能力较差 (置信度<0.5),原因可能在于部分标签的样本量较少及标签之间存在一定的相似度和交叉关系,使模型学习时遇到困难,导致正确识别该项标签的比率降低。